
Maîtrise l'Ordre d'Exécution d'une Requête SQL
Ce que j'aurais voulu avoir en tête quand j'ai commencé !

L’ordre d’exécution d’une requête SQL, une des choses clés à avoir en tête au quotidien quand on travaille avec le langage SQL, ravi de te présenter tout ça dans cette édition #6 des Insights de Dataseito. On est désormais 852🔥
Au programme
Pourquoi s’y intéresser ?
L’ordre d’exécution d’une requête SQL
Pourquoi s’intéresser à l’ordre d’exécution d’une requête SQL ?
Comprendre l'ordre d'exécution d'une requête SQL est crucial pour maîtriser le fonctionnement d’une requête ou faire de l’optimisation des requêtes.
Contrairement à ce que l’on pourrait penser instinctivement, lorsque l’on exécute une requête SQL les commandes ne s’exécutent pas dans l’ordre d’écriture de haut en bas.

Pour t’expliquer tout ça, on décortique une de mes requêtes SQL que j’utilise sur un Data Warehouse SQL Serveur :

L’ordre d’exécution d’une requête SQL
1. FROM et JOIN
La première chose est de spécifier quelles sont les données que l’on souhaite explorer et par conséquent quelles sont les tables dont a besoin.
Cela peut prendre une forme simple avec une seule table :

Ou bien on peut faire des jointures entre nos différentes tables pour les lier et les utiliser comme un ensemble :

2. WHERE
Une fois les sources de données identifiées, il est possible de filtrer les lignes récupérées selon des conditions spécifiques à l’aide de la clause WHERE :

🔔 Le WHERE intervenant avant le SELECT c’est pour cela qu’il n’est pas possible d’appeler les ALIAS utilisés dans le SELECT.

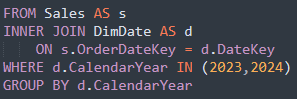
3. GROUP BY
Cette commande permet de regrouper des données avec des fonctions d’agrégation telles que : COUNT(), SUM(), AVG(), MAX() et MIN(). Très utile pour changer la granularité de nos données.
En partant d’une table qui enregistre nos ventes au quotidien, on peut les aggréger par années afin d’en avoir une synthèse et d’en extraire des insights : montant total des ventes, nombre de ventes, nombre de produits vendus, etc.
4. HAVING
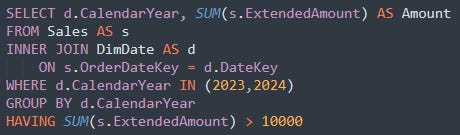
La clause HAVING fonctionne à peu près comme la clause WHERE, dans le sens où elle permet d’appliquer des filtres. La différence est qu’elle s’applique sur les groupes de lignes retournées dans le résultat du GROUP BY.
On peut ainsi l’appliquer sur les colonnes de la clause GROUP BY ou sur une fonction d’agrégation comme COUNT(), SUM(), AVG(), MAX() et MIN().

5. SELECT
On y est, c’est le moment d’appliquer le SELECT pour sélectionner les colonnes que tu souhaites récupérer dans les données spécifiées au sein des clauses FROM et JOIN.
🔔 Le SELECT est exécuté forcément après un FROM, sans cela SQL Server ne sait pas où les données se trouvent et donc il ne peut pas pointer dessus.
6. ORDER BY
Cette étape dans l’ordre d’exécution permet de choisir dans quel ordre (croissant ou décroissant) on souhaite trier les données sélectionnées.
Ainsi, tu peux trier les ventes récupérées des plus récentes aux plus anciennes.

7. LIMIT
Il existe différentes commandes qui diffèrent selon le système de gestion de base de données (SGBD) que tu utilises. Elles permettent de restreindre et limiter le nombre de lignes retournées et c’est la dernière étape de l’exécution d’une requête SQL. 😉
C’est tout pour aujourd’hui, si tu penses à quelqu’un que cela pourrait aider n’hésite pas à lui partager et à très vite 🔥
Claudio de Dataseito